In this post, I'll design a URL shortener.
Overview
A URL shortener is a service that takes a long URL and returns a shorter URL.
I'll structure this post to cover:
Requirements
Functional Requirements
I'll first scope the requirements to start adding clarity to our thinking.
- A user should be able to create a short URL using a long URL.
- The user should be able to specify a custom alias for the short URL.
- The user should be able to specify an expiration time for the short URL.
- The short URL should be unique.
- The short URL should redirect to the long URL.
Non-Functional Requirements
- Redirects should be fast (low latency) p99 < 100ms
- Scale - 100M DAU and 1B URLs
- CAP -> I will choose high availability and eventual consistency
Access Pattern: Read-to-Write Ratio is heavily skewed towards reads.
Out-Of-Scope
- Analytics
- Rate limiting
- Observability/Alerting
- Error handling
- Rate limiting/DDOS protection
Core Entities
I'll define the core entities for the system. This will help us start thinking about what data we need to store. At this point, I'll define them at a high level and we'll add more details about the exact data model as our design evolves.
- Original URL
- Short URL
- User
The Contract and API
Create a Short URL
We need a POST endpoint to create a new short URL.
POST /urls -> 201 Created
{
originalUrl
alias?
expirationTime?,
}Redirect to the Original URL
We need a GET endpoint to redirect a user to the original URL from a short URL.
We can either choose a permanent redirect or a temporary redirect.
Permanent redirect: 301 Redirect
Pros:
- Reduces the load on the server Cons:
- We lose analytics
- The expiration time feature will not work
Temporary redirect: 302 Redirect
Pros:
- We get more control over the process, in case we need to change or delete the short URL.
- We get accurate analytics
- We can set an expiration time Cons:
- We add load to the server
I'll choose the temporary redirect since the impact on the server is minimal and we get accurate analytics.
GET /{shortUrl} -> 302 Redirect to originalUrlHigh Level Design
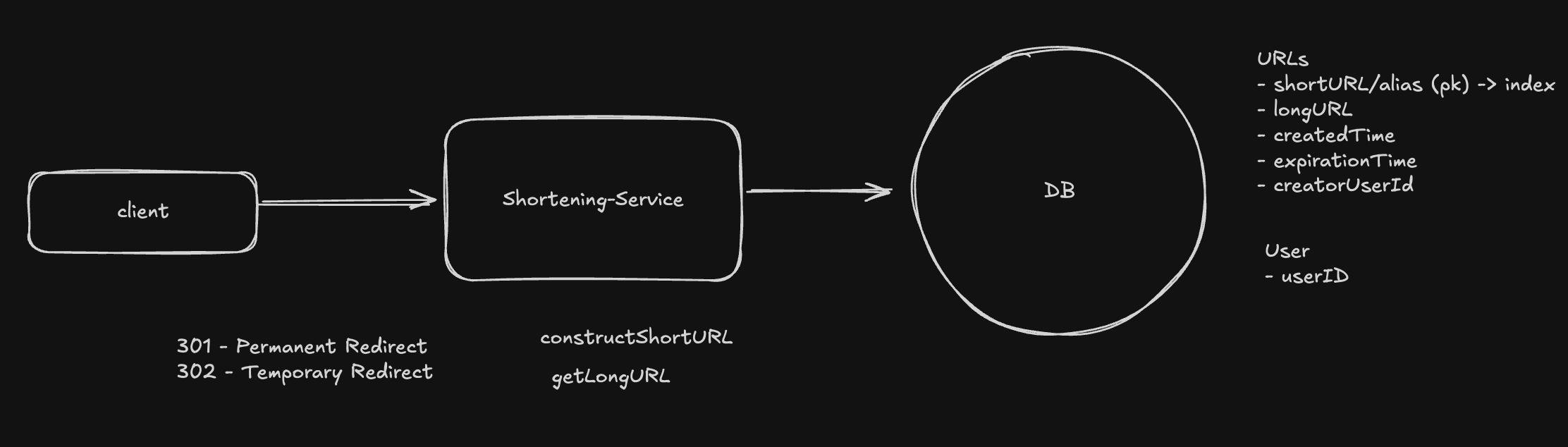
Create a Short URL
The client will send a POST request to the server with the original URL, alias, and expiration time.
We should validate that the url is valid, and doesn't already exist in our system.
import isUrl from 'is-url-superb'
isUrl(originalUrl)If the user provided an alias, we should validate that it hasn't already been taken. The expiration time should be a valid date in the future.
Our service will generate a short URL, store the relevant data to the database, and return the short URL to the client. I'll discuss how to generate a short URL that is unique in the next section.
We can optionally cleanup URLs that have an expiration time in the past. However, we can consider such rows as soft-deleted by ignoring them at read time.
Redirect to the Original URL
The client will send a GET request to the server with the short URL.
We will lookup the short URL in the database and, if it hasn't expired, redirect the client to the original URL.
Short URL should be unique
Option 1: Unpredictable Input + Hash Function
Here's a simple implementation of this approach.
import normalizeUrl from 'normalize-url'
import {createHmac} from 'node:crypto'
import basex from 'base-x'
const BASE62_ALPHABET =
'0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz'
const base62 = basex(BASE62_ALPHABET)
const originalUrl = 'https://www.example.com/some/long/path/to/a/resource'
// canonicalize the url
const normalizedUrl = normalizeUrl(originalUrl)
// hash the url
const salt = 'salt'
const hash = createHmac('sha256', salt).update(normalizedUrl).digest('hex')
// base62 encode the hash
const base62EncodedHash = base62.encode(Buffer.from(hash))
const shortCode = base62EncodedHash.slice(0, 6)There's still a chance of collision with this approach - with the chance being higher if the number of characters in the short code is lower. We would need to query the database to check if the short code is already in use. See Birthday paradox - only 23 individuals are required to reach a 50% probability of a shared birthday.
This is a good approach for a small scale system (as the probability of collision stays low enough). However, given the scale of our system, we need to consider a more robust approach.
Option 2: Incremental Counter
I'll use a unique counter which I base62 encode to get the short code. This guarantees uniqueness without the need to query the database. I'll use Redis with the INCR command to increment the counter. Redis is single-threaded, and INCR is atomic. I'll have to think about how this would work in a distributed system. This could cause security concerns, since the counter is predictable and could be guessed. We can use a bijective function to make the counter unpredictable.
With a 6 character short code, we can represent 62^6 => ~56.8 billion unique short codes.
function toBase62(num) {
const ALPHABET =
'0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz'
// Validate input
if (!Number.isInteger(num) || num < 0) {
throw new Error('Number must be a non-negative integer')
}
// Handle zero case
if (num === 0) {
return '0'
}
// Build result array for better performance
const result = []
let n = num
while (n > 0) {
result.push(ALPHABET[n % 62])
n = Math.floor(n / 62)
}
return result.reverse().join('')
}
const counter = 0
const shortCode = toBase62(counter)
// for counter = 56_800_235_583 -> shortCode = zzzzzz
// 1_000_000_000 -> 15ftgG
Obfuscation
We make use of a bijective function to make the counter unpredictable. A bijective function is a function that is both injective and surjective. Injective means that each input has a unique output, and surjective means that each output has a unique input. This ensures that the counter is unpredictable and that the short code is unique.
Here are some examples of using a bijective function to make the counter unpredictable.
XOR with a large prime
Note: This must be tested across the entire range since the range of 32-bit integers is limited. We can make use of BigInt to handle the larger range.
// Obfuscation using XOR with a large prime
const OBFUSCATION_PRIME = 2654435761 // Keep this secret!
function obfuscateCounter(counter) {
// Convert to unsigned 32-bit integer before XOR
const counterUint = counter >>> 0
const primeUint = OBFUSCATION_PRIME >>> 0
// XOR and ensure result is unsigned
const obfuscated = (counterUint ^ primeUint) >>> 0
return obfuscated
}
function unobfuscateCounter(obfuscated) {
const obfuscatedUint = obfuscated >>> 0
const primeUint = OBFUSCATION_PRIME >>> 0
// XOR again to reverse (XOR is its own inverse)
return (obfuscatedUint ^ primeUint) >>> 0
}
const shortCode = toBase62(obfuscateCounter(counter))Permuted Alphabet
// Shuffled alphabet (keep this secret!)
const PERMUTED_ALPHABET =
'k3jF9mNpQrS7tUvWxYzA2B4C6D8E0G1H5IaLbMcOdPeRfTgVhXiYjKlMn'Modular Arithmetic
const MODULUS = 62 ** 6 // Maximum value for 6 characters
const MULTIPLIER = 2654435761 // Must be coprime to MODULUS
const INVERSE = 1234567890 // Calculate using extended Euclidean algorithm
function obfuscateCounter(counter) {
const obfuscated = (counter * MULTIPLIER) % MODULUS
return obfuscated
}
function unobfuscateCounter(obfuscated) {
return (obfuscated * INVERSE) % MODULUS
}Deep Dives
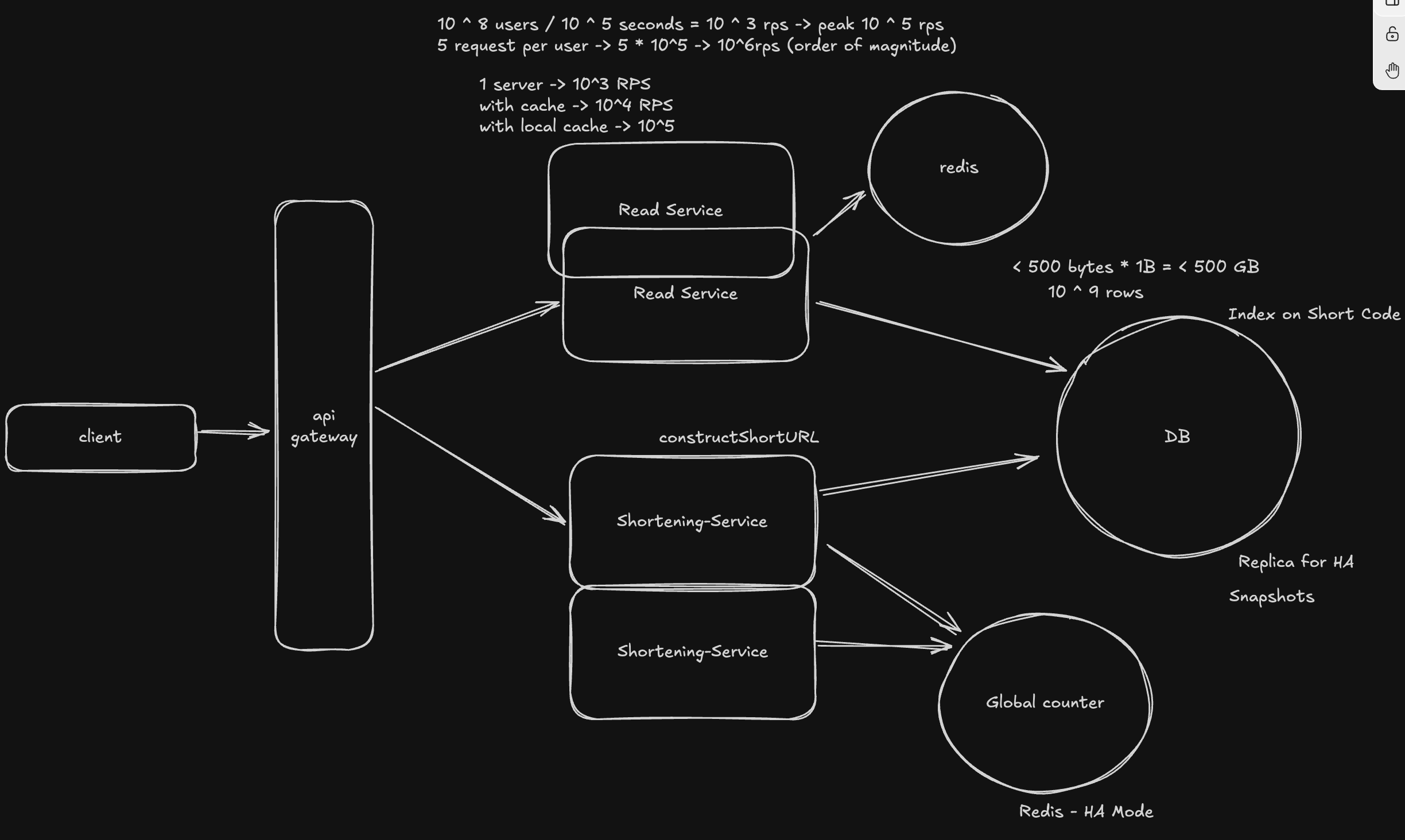
Redirects Should be Fast
We need to first measure the current latency of the redirect endpoint. We need to have observability in place. We'll also run some load tests and do some profiling. This will help us understand the bottlenecks and where we should focus our optimizations effort.
Database Indexing
We'll create an index on the short URL column. Our options here are to choose a B-tree index (the default) or a hash index. A B-tree index would work fine for this case.
100M DAU -> 10^2 * 10^6 * 5 (assuming 5 requests per user per day) = 500M reads per day With 10^5 seconds in a day, we get: ~5000 reads per second To handle spikes, this could mean 500,000 reads per second at peak times.
Even with an index, this would be too much for a single DB instance to handle (modern SSDs can handle 100,000+ IOPS).
Caching
We'll introduce a cache layer, which reduces the need to call the database. A read-through (or cache aside) pattern would work well here. We'll use LRU as the eviction policy. Redis would be a good fit for this.
This not only reduces the load on the database, but also reduces the latency of the redirect endpoint.
Memory access time: ~100 nanoseconds (0.0001 ms)
SSD access time: ~0.1 milliseconds
HDD access time: ~10 milliseconds
In-memory access is 1000x faster than SSD access.The trade-off here is adding complexity to our application, adding a new component (which incurs cost). Cache invalidation can also be tricky, if not implemented correctly, we could end up with stale data or security issues.
CDNs
We'll try to serve the redirect from a CDN - which can be considered as a globally distributed cache. This would reduce the latency for a global audience, reduce the load on our server (and by extension, the database).
There are multiple ways to configure this.
Pull from Origin
We configure the CDN to cache the response from the origin server after the first request. This is simple and cost-effective, but a key challenge is handling expiration and invalidation.
Static Configuration
The CDN can redirect the user to the original URL based on a static configuration. This will be fast and cost-effective, but has limited scalability, slow-to-update and static. We will have to rely on the CDN provider for analytics.
Edge Functions
Dynamic functions that fetch mapping in realtime. This would incur high cost, but would be more flexible and scalable.
Edge KV
Here, we store the mapping in the CDN itself. The cost can be even higher at high volumes. However, this adds further complexity, and invalidation of data stored in the CDN can be tricky. Similarly, cost is another factor to consider.
Scale - 100M DAU and 1B URLs
Database
Size of Data: Short Code: 8 bytes Original URL: 100 bytes Created At: 8 bytes Expiration Time: 8 bytes We need to store ~200 bytes, which we can round up to ~500 bytes per row. With 1B URLs, 500 bytes * 10^9 = 500 GB Here, I'll opt for a vertical scaling approach - a single modern server should be able to handle this. We will of course, add a replica for high availability. We'll also have regular snapshots to ensure data integrity. We can also add read replicas for read scalability. However, at this scale, we do not need to worry about horizontal scaling. Both a SQL and a NoSQL database would be able to handle this.
Similarly, our cache server can also be scaled vertically - the storage requirements for that would be much less, since we will only store the most recently used URLs.
Application Server
Since we have very different access patterns for reads and writes, I'll break down the application server into two components:
- Redirect Service (Read-only server)
- Shortening Service (Write-only server)
We can then scale the Redirect Service horizontally. If needed, the Shortening Service can also be scaled - the number of replicas here will likely be much less. One complexity we've introduced here is we now need to keep the counter in sync between different write servers. For this, we can use a separate Redis instance. To reduce latency, we fetch a batch of counters - use them and then fetch the next batch. Redis also has automatic failover (Redis Sentinel) to ensure high availability.
Conclusion
My design now meets both our functional and non-functional requirements without being over-engineered.
Useful Links
- Write up on HelloInterview
- Solution (for Pastebin) by System Design Primer
- Birthday paradox
- Hash Indexes on Postgres